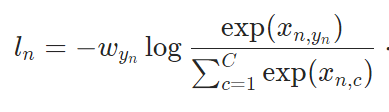Tensorboard的使用
from torch.utils.tensorboard import SummaryWriter
help(SummaryWriter)
"""
将条目直接写入 log_dir 中的事件文件以供 TensorBoard 使用。 `SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件并向其中添加摘要和事件。该类异步更新文件内容。这允许训练程序调用方法直接从训练循环将数据添加到文件中,而不会减慢训练速度。
"""Tensorboard 写日志
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 创建一个logs文件夹,writer写的文件都在该文件夹下
#writer.add_image()
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
"""def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
scalar_value (float or string/blobname): Value to save
global_step (int): Global step value to record
scalar_value是y轴
global_step是x轴
"""Tensorboard 读日志
tensorboard --logdir==logs #不指定端口
tensorboard --logdir==logs --port==6007 #指定端口
tensorboard --logdir=D:\Users\Zmaster\Desktop\Degree\github\SeismicNet\output\logs\unetPPTensorboard 读图片
注意这里的img_tensor参数只接受torch.Tensor, numpy.array, or string/blobname类型的数据!!!
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats=‘CHW’):
img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
import os
print("当前工作目录:", os.getcwd())
img_path1 = "data/train/ants_image/0013035.jpg"
img_PIL1 = Image.open(img_path1)
img_array1 = np.array(img_PIL1)
img_path2 = "data/train/bees_image/16838648_415acd9e3f.jpg"
img_PIL2 = Image.open(img_path2)
img_array2 = np.array(img_PIL2)
writer = SummaryWriter("logs")
writer.add_image("test",img_array1,1,dataformats="HWC") # 1 表示该图片在第1步
writer.add_image("test",img_array2,2,dataformats="HWC") # 2 表示该图片在第2步
writer.close()
nn.Module模块使用
① nn.Module是对所有神经网络提供一个基本的类。
② 我们的神经网络是继承nn.Module这个类,即nn.Module为父类,nn.Module为所有神经网络提供一个模板,对其中一些我们不满意的部分进行修改。
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__() # 继承父类的初始化
def forward(self, input): # 将forward函数进行重写
output = input + 1
return output
tudui = Tudui() #使用Tudui()模板创建了一个名为tudui的神经网络
x = torch.tensor(1.0) # 创建一个值为 1.0 的tensor
output = tudui(x)
print(output)
forward
forward() 函数主要的作用就是定义如何将输入的数据经过神经网络的各个层进行计算,并输出最终的结果。 在自定义神经网络模型中,我们需要重写 nn.Module 类中的 forward() 函数。
① 使用pytorch的时候,不需要手动调用forward函数,只要在实例化一个对象中传入对应的参数就可以自动调用 forward 函数。
② 因为 PyTorch 中的大部分方法都继承自 torch.nn.Module,而 torch.nn.Module 的__call__(self)函数中会返回 forward()函数 的结果,因此PyTroch中的 forward()函数等于是被嵌套在了__call__(self)函数中;因此forward()函数可以直接通过类名被调用,而不用实例化对象。
Module — PyTorch 2.2 documentation
官网例子
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x): #输入:x
x = F.relu(self.conv1(x)) #self.conv1(x) 卷积 relu:非线性
return F.relu(self.conv2(x)) #F.relu(self.conv2(x)) 再经过一次卷积和非线性
卷积操作
① 卷积核不停的在原图上进行滑动,对应元素相乘再相加。
② 下图为每次滑动移动1格,然后再利用原图与卷积核上的数值进行计算得到缩略图矩阵的数据,如下图右所示。
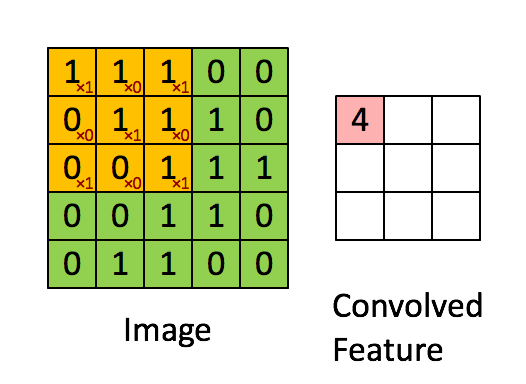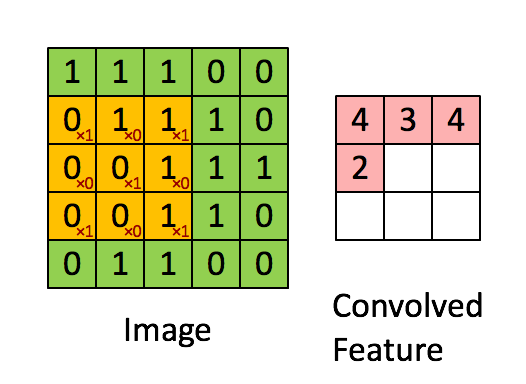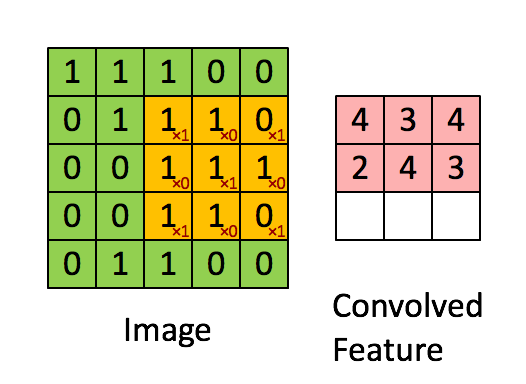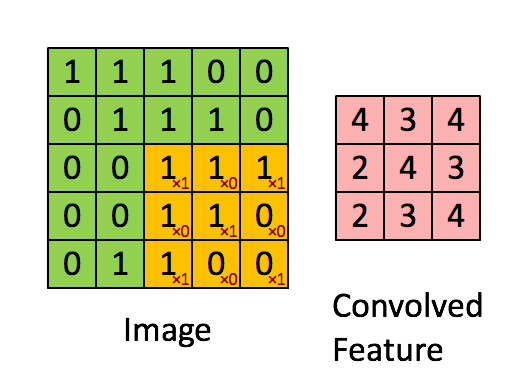
例子:
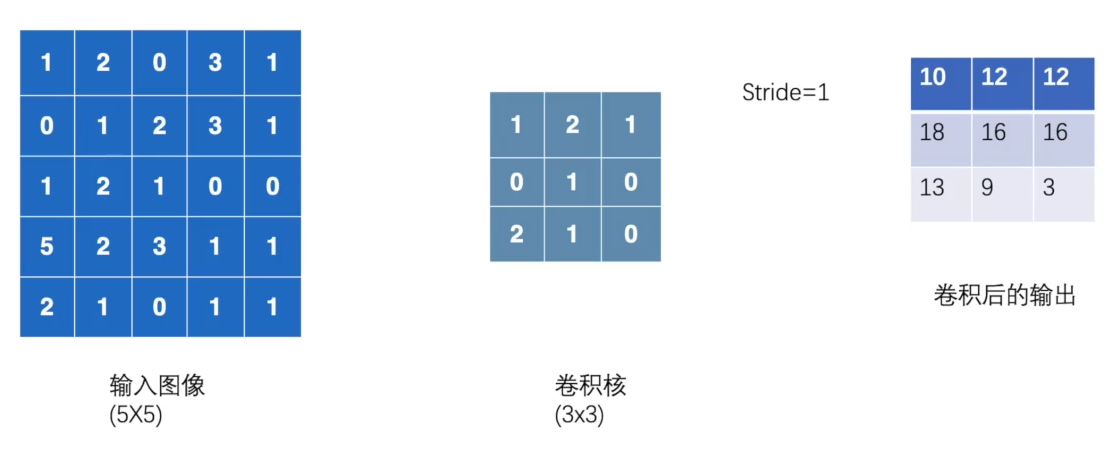
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
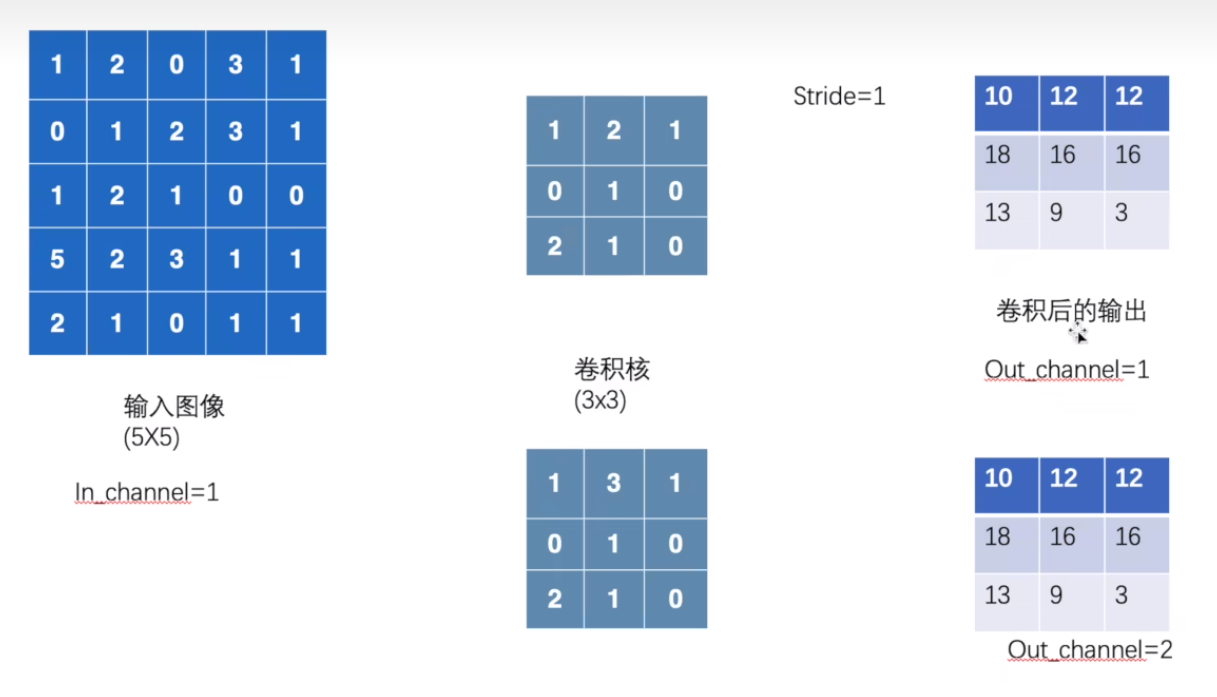
output = F.conv2d(input, kernel, stride=1)
print(output)
输出:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])stride
步幅:卷积核经过输入特征图的采样间隔。
设置步幅的目的:希望减小输入参数的数目,减少计算量。
例子1:一个特征图尺寸为4 * 4的输入,使用3 * 3的卷积核,步幅=1,填充=0,输出的尺寸=(4 - 3)/1 + 1 = 2。
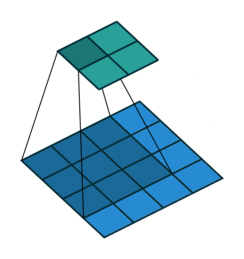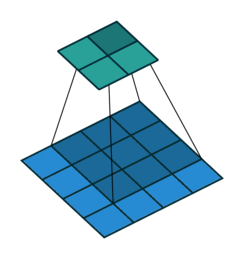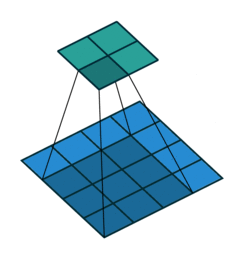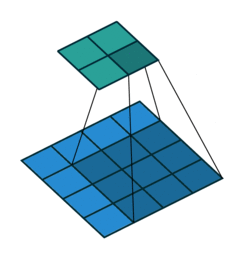
例子2:一个特征图尺寸为5 * 5的输入, 使用3 * 3的卷积核,步幅=2,填充=0,输出的尺寸=(5-3)/2 + 1 = 2。
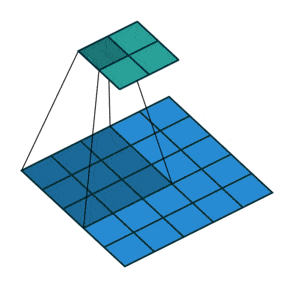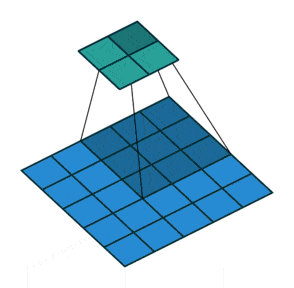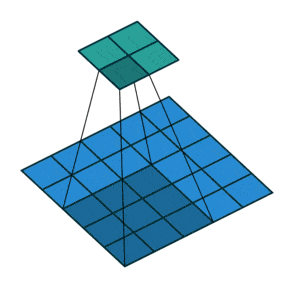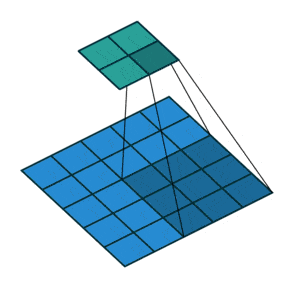
例子:步幅为2
相当于卷积核一次移动两格
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
output2 = F.conv2d(input, kernel, stride=2) # 步伐为2
print(output2)
输出:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12],
[13, 3]]]])padding
填充:在输入特征图的每一边添加一定数目的行列。
设置填充的目的:希望每个输入方块都能作为卷积窗口的中心,或使得输出的特征图的长、宽 = 输入的特征图的长、宽。
例子: 一个特征图尺寸为5 * 5的输入,使用3 * 3的卷积核,步幅=1,填充=1,输出的尺寸=(5 + 2 * 1 - 3)/1 + 1 = 5。
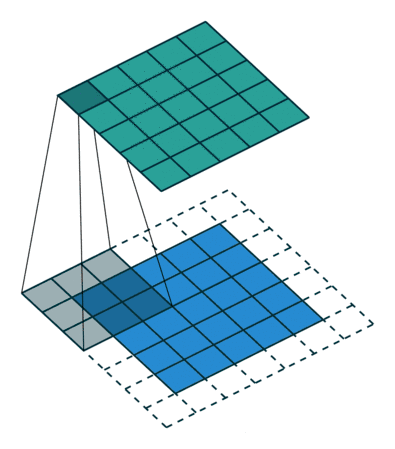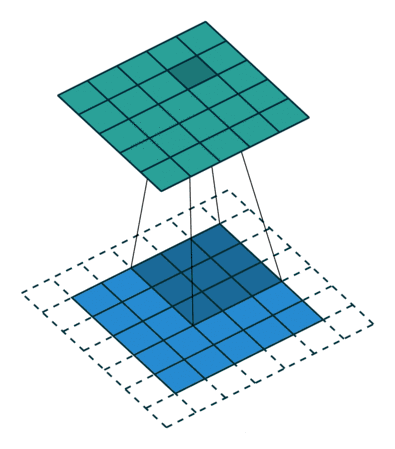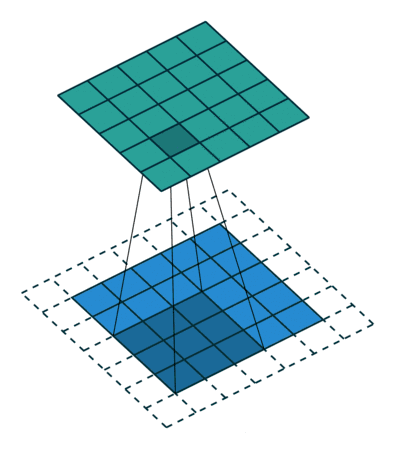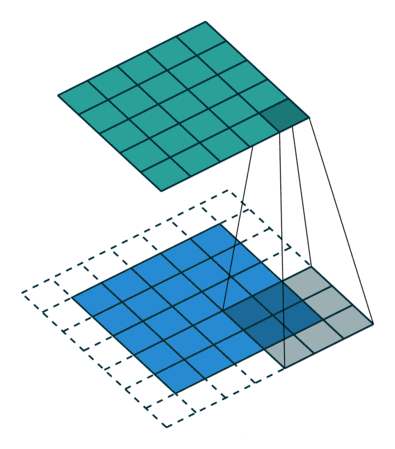
例子:padding = 1
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
output3 = F.conv2d(input, kernel, stride=1, padding=1) # 周围只填充一层
print(output3)输出:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])padding与stride结合起来看
例子:一个特征图尺寸为6 * 6的输入, 使用3 * 3的卷积核,步幅=2,填充=1,输出的尺寸=(6 + 2 * 1 - 3)/2 + 1 = 2.5 + 1 = 3.5 向下取整=3(降采样:边长减少1/2)。
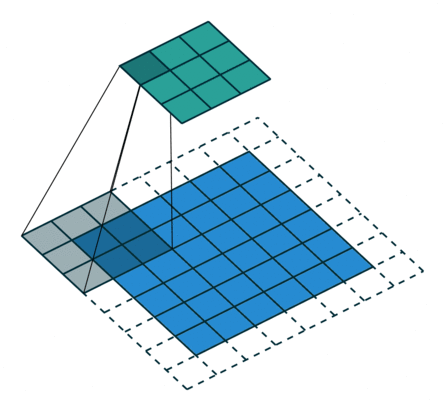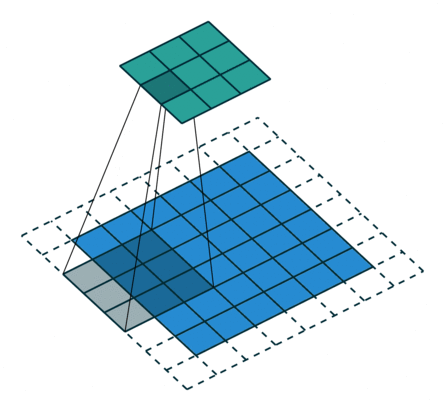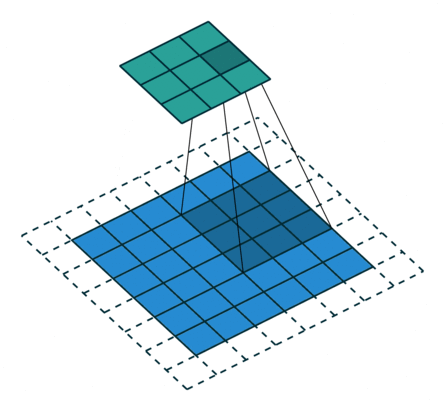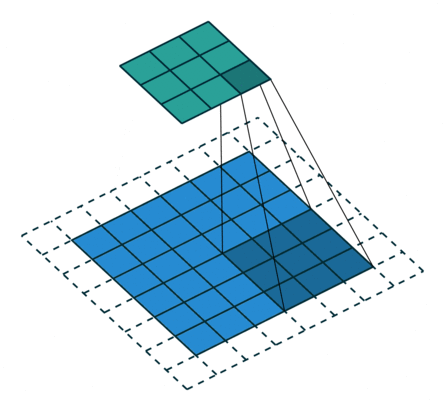
卷积的输入输出
① Conv1d代表一维卷积,Conv2d代表二维卷积,Conv3d代表三维卷积。
② kernel_size在训练过程中不断调整,定义为3就是3 * 3的卷积核,实际我们在训练神经网络过程中其实就是对kernel_size不断调整。
③ 可以根据输入的参数获得输出的情况,如下图所示
输入输出格式

当你设置Out_channel = 2 的时候,卷积层就会生成两个卷积核,从而得到2个输出,如下图:
搭建卷积层
import torch
from torch import nn
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) # 彩色图像输入为3层,我们让它的输出为6层,选的是3 * 3 的卷积
def forward(self,x):
x = self.caonv1(x)
return x
tudui = Tudui()
print(tudui)输出网络的结构如下:
Tudui(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)
卷积层处理图片
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) # 彩色图像输入为3层,我们想让它的输出为6层,选3 * 3 的卷积
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape) # 输入为3通道32×32的64张图片
print(output.shape) # 输出为6通道30×30的64张图片
Tensorboard显示
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) # 彩色图像输入为3层,我们想让它的输出为6层,选3 * 3 的卷积
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# 输入大小:torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# 输出大小:torch.Size([64, 6, 30, 30]) --> [xxx,3,30,30] 才能正常显示
output = torch.reshape(output,(-1,3,30,30)) # 把原来6个通道拉为3个通道,为了保证所有维度总数不变,其余的分量分到第一个维度中
writer.add_images("output", output, step)
step = step + 1
池化
常用2D最大池化,池化使得数据由5 * 5 变为3 * 3,甚至1 * 1的,这样导致计算的参数会大大减小。例如1080P的电影经过池化的转为720P的电影、或360P的电影后,同样的网速下,视频更为不卡。
例:torch.nn.MaxPool2d
MaxPool2d — PyTorch 2.2 documentation
Parameters
-
kernel_size (Union[int, Tuple[int, int]__]) – the size of the window to take a max over
-
stride (Union[int, Tuple[int, int]__]) – the stride of the window. Default value is
kernel_size -
padding (Union[int, Tuple[int, int]__]) – Implicit negative infinity padding to be added on both sides
-
dilation (Union[int, Tuple[int, int]__]) – a parameter that controls the stride of elements in the window
-
return_indices (bool) – if
True, will return the max indices along with the outputs. Useful fortorch.nn.MaxUnpool2dlater -
ceil_mode (bool) – when True, will use ceil instead of floor to compute the output shape
注意这里stride的默认值是kernel_size
Shape

ceil_mode
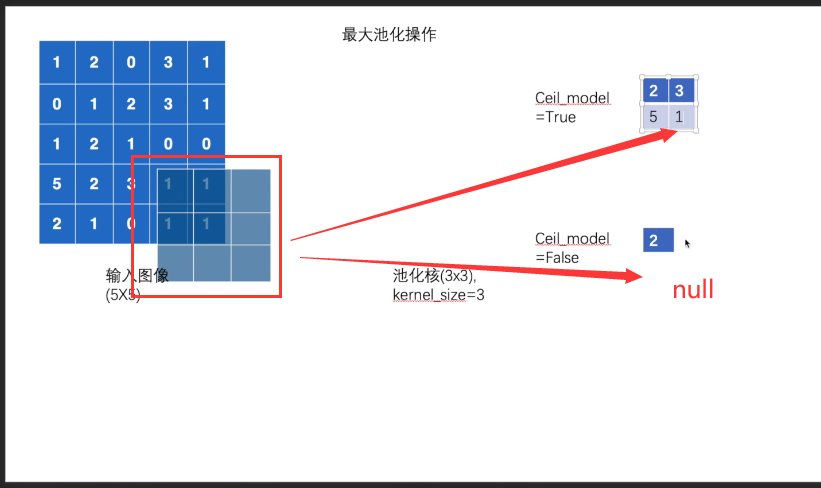
例子:
ceil_mode = true 的时候 ,(取值为1 框框中的最大值)
ceil_mode = false的时候,直接舍弃
dilation
为空洞卷积,如下图所示。
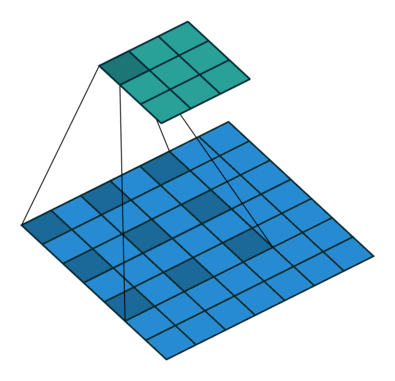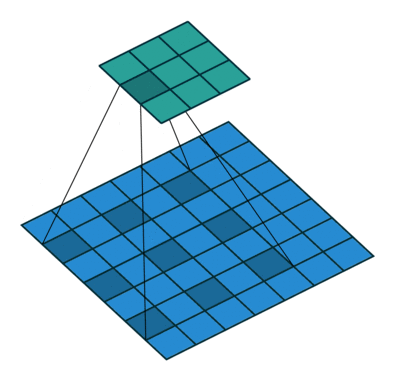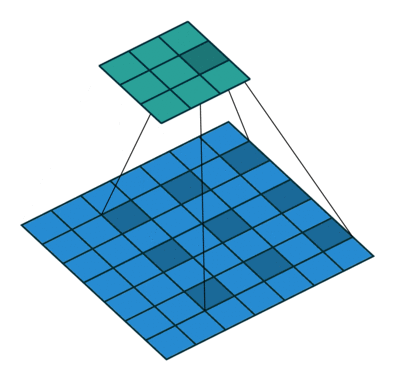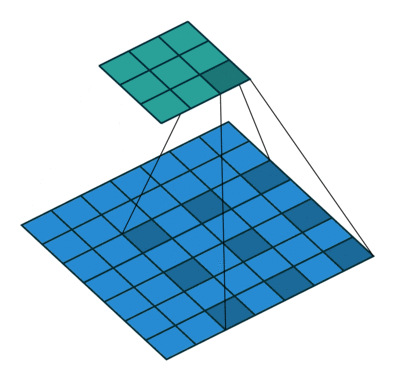
池化层处理数据
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]], dtype = torch.float32) #最大池化需要用浮点数
input = torch.reshape(input,(-1,1,5,5))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True) #创建池化层
def forward(self, input):
output = self.maxpool(input) #把input放入最大池化层
return output
tudui = Tudui() #创建神经网络
output = tudui(input) #把输入送入创建好的神经网络中
print(output)
输出
ceil_mode=True时
torch.Size([1, 1, 5, 5])
tensor([[[[2., 3.],
[5., 1.]]]])ceil_mode=false时
torch.Size([1, 1, 5, 5])
tensor([[[[2.]]]])与前文ceil_mode手动计算结果一致
池化层处理图片
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True) #创建池化层
def forward(self, input):
output = self.maxpool(input) #把input放入最大池化层
return output
tudui = Tudui() #创建神经网络
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
tensorbord查看:
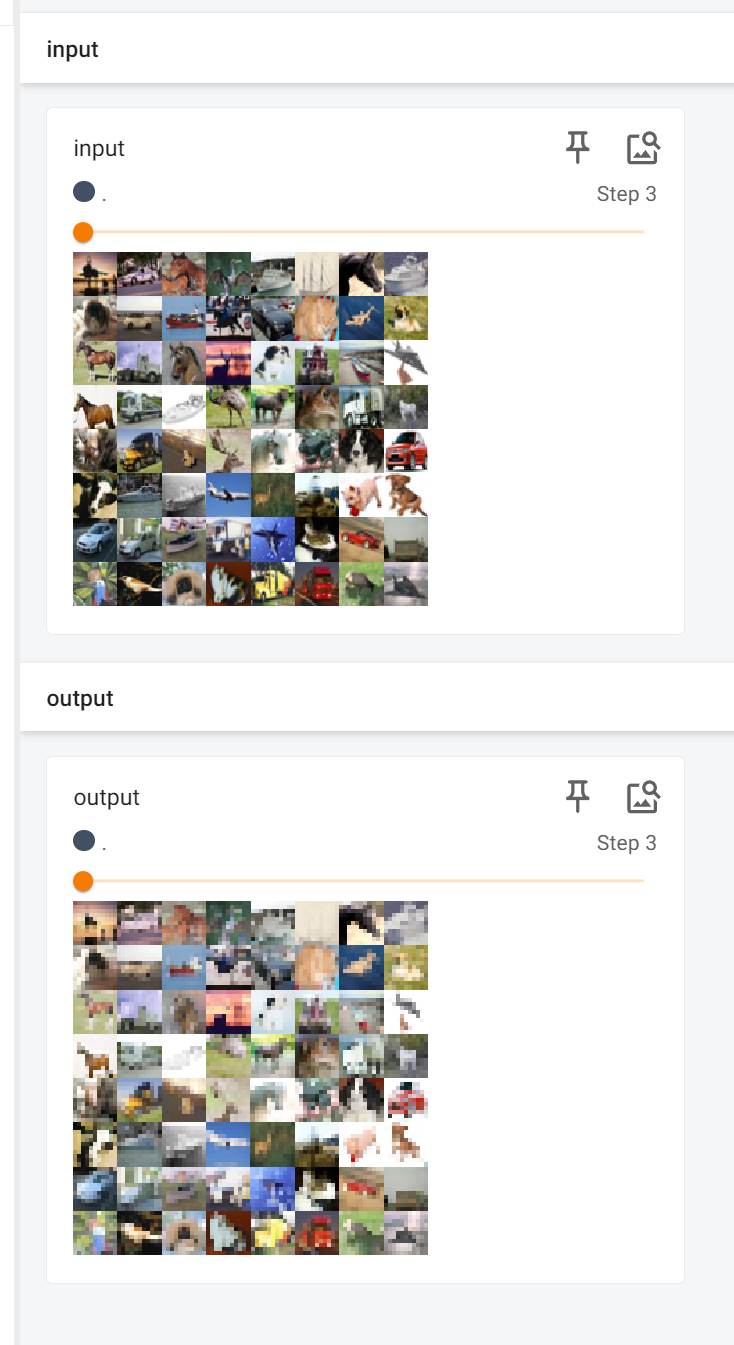
非线性激活
非线性越多的话,才能训练出符合各种曲线或者各种特征的模型,如果都是直愣愣的话模型的泛化能力就会不够好。
Non-linear Activations (weighted sum, nonlinearity)
Non-linear Activations (other)
ReLU — PyTorch 2.2 documentation
例子ReLU
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
输出:
torch.Size([1, 1, 2, 2])
tensor([[[[1., 0.],
[0., 3.]]]])例子Sigmoid
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
Sequential使用
把网络结构放在Sequential里面,好处就是代码写起来比较简介、易懂。
例子
创建一个如下图所示的网络
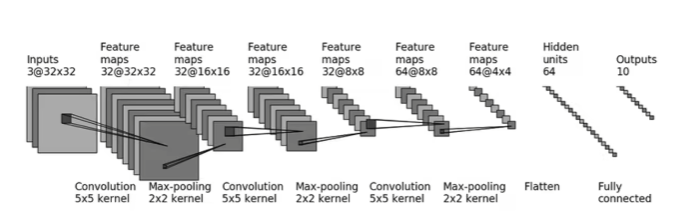
可以根据神经网络每层的尺寸,根据 [Shape](### Shape ) 如下图的公式计算出神经网络中的参数。
搭建神经网络
之前的方式:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3,32,5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,5,padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024,64)
self.Linear2 = Linear(64,10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.Linear2(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)
输出:
Tudui(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(cov2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(Linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])Sequential搭建神经网络
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)
输出:
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])Tensorboard显示网络
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
writer = SummaryWriter("logs")
tudui = Tudui()
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)
writer.add_graph(tudui, input) #add_graph输入模型和input数据
writer.close()